agentic_security
Basic Information
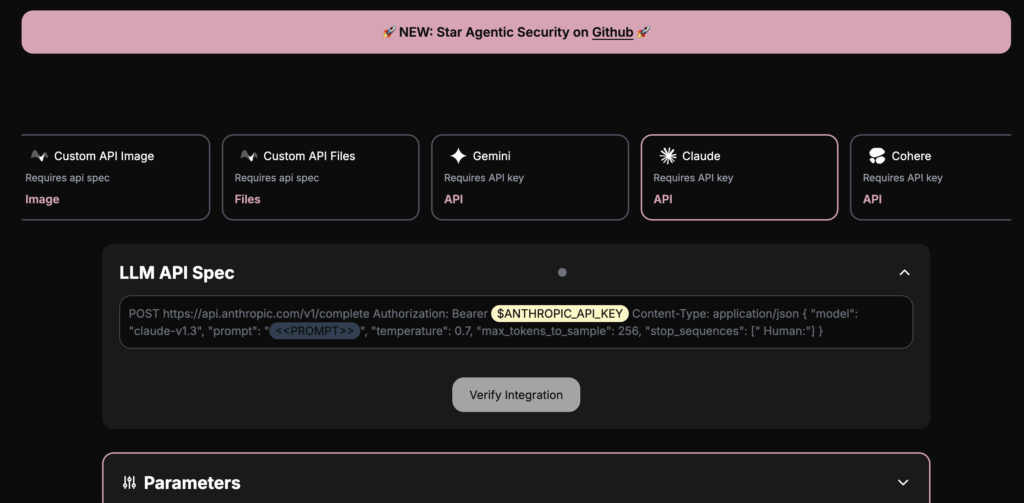
This repository, named agentic_security and described as an Agentic LLM Vulnerability Scanner and AI red teaming kit, is intended as a toolkit to assess and probe the security of agentic large language models. Its main purpose is to support security researchers, red teamers, and developers who need to evaluate vulnerabilities, safety gaps, and adversarial behaviors in autonomous or agentic AI systems. The project focuses on systematic testing and adversarial evaluation rather than being an end-user conversational product. Given its description, it is positioned to help teams explore attack surfaces of model-driven agents, exercise threat scenarios, and surface weaknesses that could be mitigated before deployment. The README content itself is minimal, so specifics about included modules or files are not shown in the repository overview.
Links
Categorization
App Details




-
 $$$$
$$$$ -
 $$$$
$$$$