voice-chat-ai
Basic Information
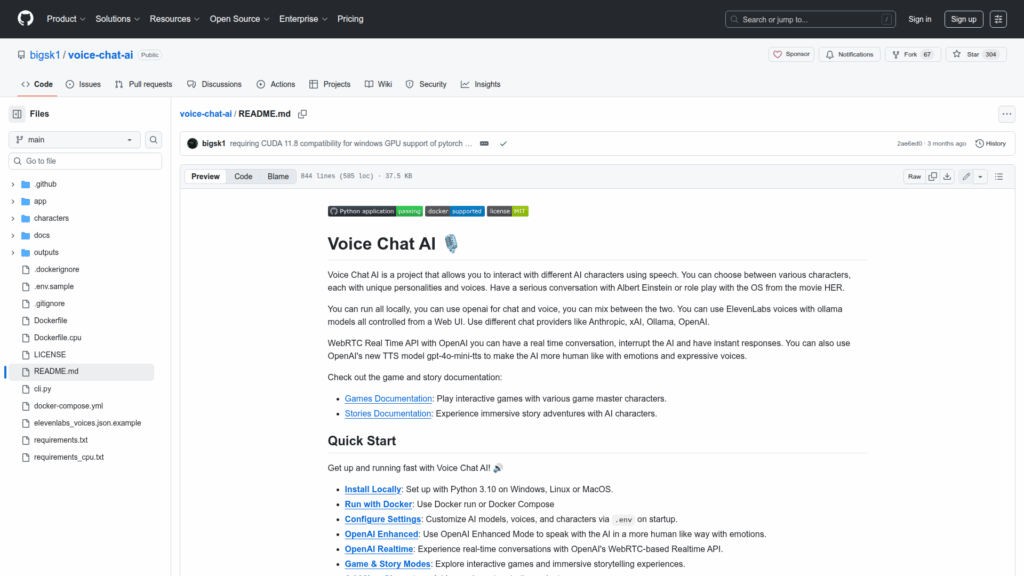
Voice Chat AI is an application for interacting with AI characters using natural speech. It is designed to run locally or in Docker and can connect to multiple chat model providers including OpenAI, xAI, Anthropic and Ollama. Users can choose from a large library of built-in characters, add new characters by providing a prompt and mood prompts, and switch TTS and transcription providers on the fly via a Web UI or a feature-rich terminal CLI. The project supports real-time WebRTC conversations with OpenAI Realtime for continuous, interruptible voice exchanges and also offers local options such as XTTS, Kokoro TTS and Faster Whisper transcription for offline or GPU-accelerated setups. Configuration is handled through a .env file and the app is served via uvicorn on port 8000.
Links
Categorization
App Details




-
 $$$$
$$$$ -
 $$$$
$$$$