Basic Information
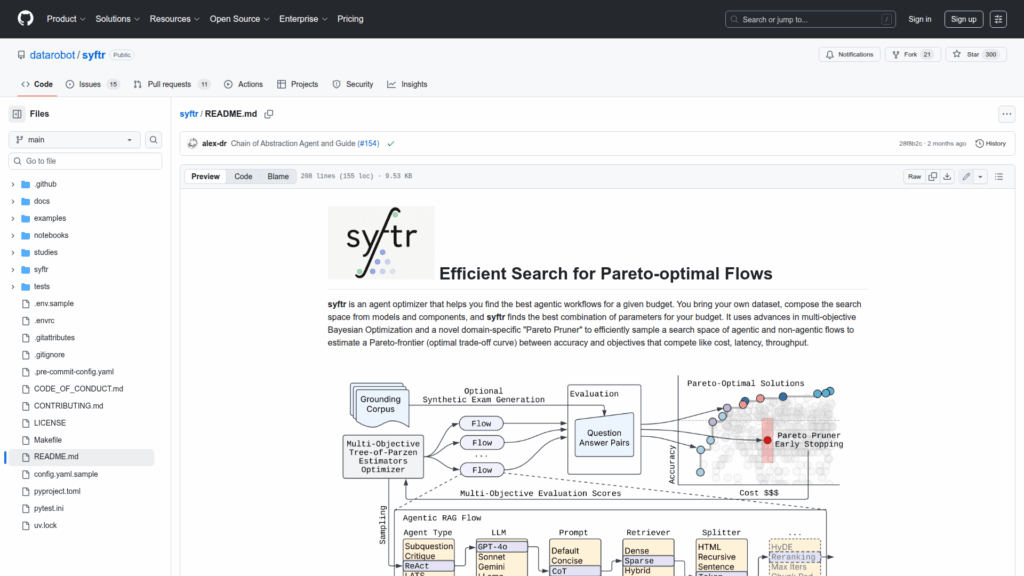
syftr is an agent optimizer designed to find Pareto-optimal agentic and non-agentic workflows for a given budget and competing objectives. It lets users supply datasets and compose a search space of models and flow components, then runs an efficient multi-objective search to estimate a Pareto frontier that trades off accuracy against costs such as LLM token cost, latency, and throughput. syftr implements multi-objective Bayesian optimization together with a domain-specific Pareto Pruner to focus sampling on promising configurations. It functions as a library and a CLI with example studies and Jupyter notebooks, requires a config.yaml for LLM and infrastructure settings, and outputs discovered Pareto flows and associated metrics. The project integrates with distributed execution and is intended for researchers and engineers exploring cost-accuracy trade-offs in agentic pipelines.
Links
Categorization
App Details




-
 $$$$
$$$$ -
 $$$$
$$$$