SearchLM
Basic Information
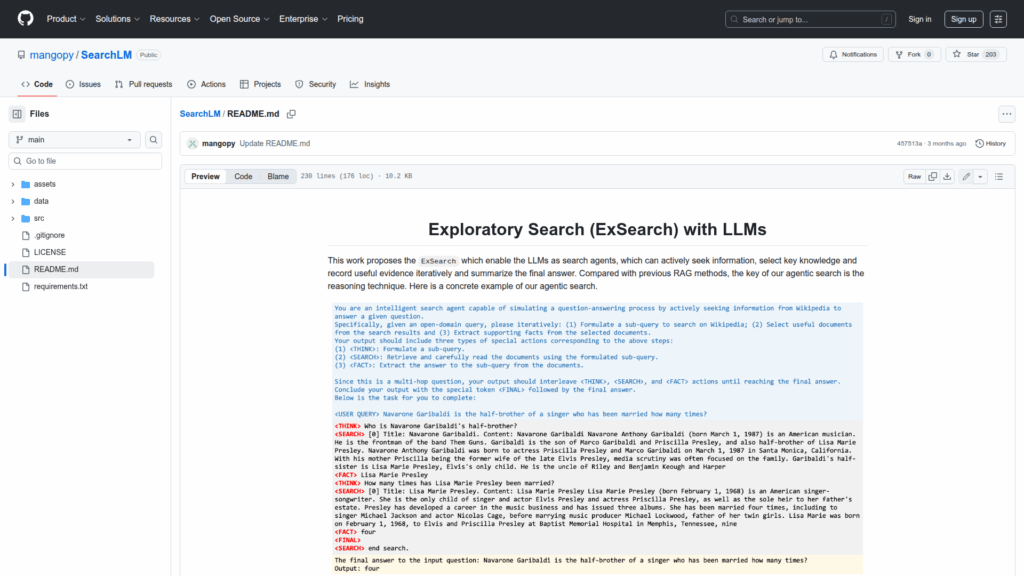
This repository implements ExSearch, an agentic search approach that enables large language models to act as active search agents that iteratively seek information, select key knowledge, record evidence, and summarize final answers. It is intended for researchers and developers who want reproducible code and data for training LLMs to perform retrieval-augmented, reasoning-driven search as an alternative to standard RAG pipelines. The README documents environment setup, retrieval corpus choices, warmup dataset creation, an alignment/self-training loop (inference, entropy estimation, formatting, learning), evaluation on QA benchmarks, and distribution of preprocessed data and trained checkpoints to support experiments and inference.
Links
Stars
207
Language
Github Repository
Categorization
App Details
Features
Provides end-to-end code and scripts for warmup training and iterative self-training driven by agentic search trajectories. Includes run scripts that support distributed training and deepspeed configurations, modular retrieval integration via src/utilize/apis.py so users can plug ColBERT or custom retrievers, and procedures for inference, entropy computation, dataset formatting and supervised fine-tuning. Supplies preprocessed evaluation data artifacts, a warmup synthetic dataset, evaluation using F1/EM/Accuracy with KILT evaluation scripts, optional wandb logging, environment hints for vllm, and published model checkpoints from the authors to run inference or reproduce results.
Use Cases
Helps researchers reproduce and extend experiments that teach LLMs to perform exploratory, agentic search rather than only passively retrieving context. Users get a warmup dataset and training pipeline to initialize models, alignment steps that generate and weight trajectories with entropy, and modular retrieval hooks to test different search backends. The repo also provides preprocessed benchmark splits and evaluation tooling so developers can compare performance on multi-hop QA datasets, leverage released checkpoints to run inference immediately, and adapt the training or retrieval pieces for their own research or production prototypes.




-
 $$$$
$$$$ -
 $$$$
$$$$