Basic Information
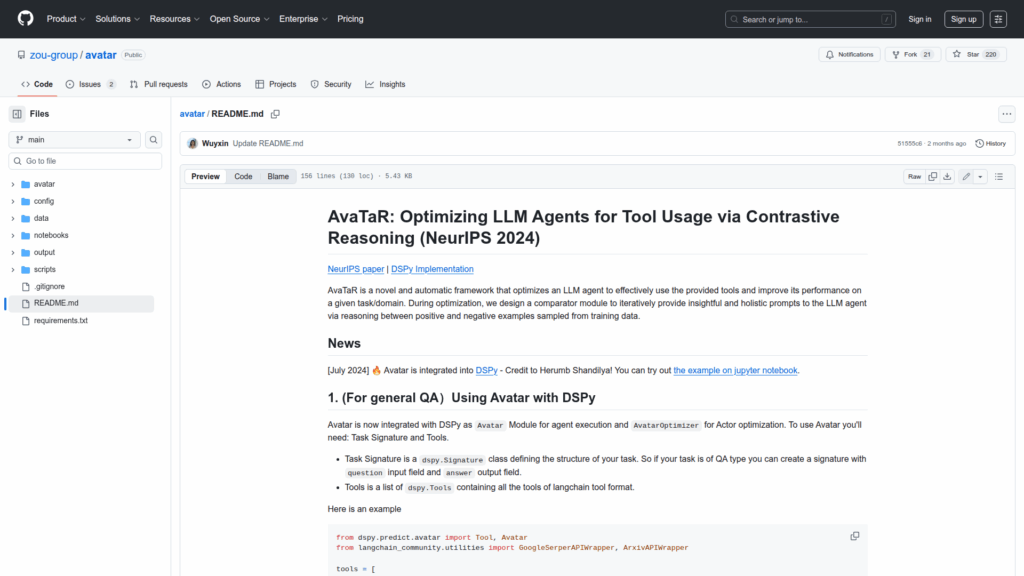
AvaTaR is a research codebase that implements a framework for optimizing large language model agents to use external tools more effectively, as presented in a NeurIPS 2024 paper. The repository provides the Avatar module and an AvatarOptimizer teleprompter that iteratively improves an agent by contrastive reasoning between positive and negative examples sampled from training data. It is intended for researchers and developers who want to adapt or reproduce the AvaTaR optimization pipeline, run experiments, or integrate the optimizer into existing agent systems. The README documents integration with the DSPy library, required task signatures and tool formats, instructions to set API keys, and dataset-specific setup for STaRK and Flickr30k Entities to reproduce experiments.
Links
Categorization
App Details




-
 $$$$
$$$$ -
 $$$$
$$$$