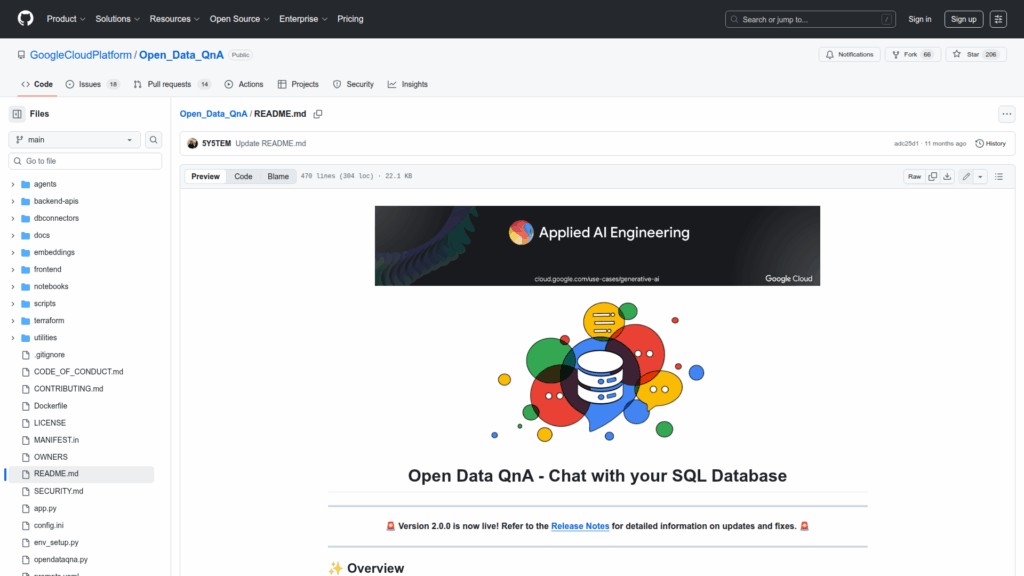
Open_Data_QnA
Basic Information
Open Data QnA is a Python-based solution accelerator and library that enables conversational access to SQL databases by leveraging LLM agents on Google Cloud. It is designed to let users ask natural language questions against PostgreSQL (Cloud SQL) and BigQuery datasets and receive SQL-generated queries, validated results, and natural language responses without requiring SQL knowledge. The repository provides modular components including database connectors, vector stores, agent implementations, notebooks, a CLI, Terraform deployment scripts, and optional frontend and backend APIs. It targets developers and teams who want to build or deploy chat-driven data exploration tools on GCP using Python, Vertex AI embeddings, Firestore for session logs, and optional PGVector or BigQuery vector stores. The README documents setup options, prerequisites such as Python >= 3.10 and Google Cloud CLI, and deployment workflows for notebooks, CLI runs, or Terraform.
Links
Categorization
App Details



-
 $$$$
$$$$ -
 $$$$
$$$$