Basic Information
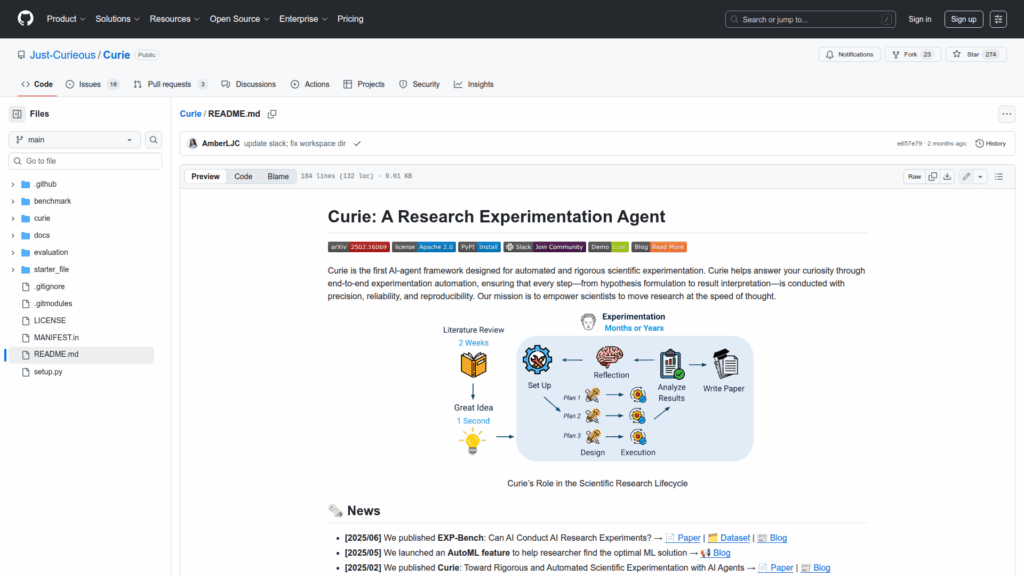
Curie is an AI-agent framework designed to automate rigorous scientific experimentation. The repository provides tools to orchestrate an end-to-end research workflow that covers hypothesis formulation, experiment implementation, execution, verification, analysis and automated reporting. It targets researchers and developers who want reproducible, methodical experiments in areas such as machine learning engineering and system analysis. Curie accepts user-provided starter code and datasets, can perform automated model and strategy searches via an AutoML feature, and produces reproducible artifacts such as experiment scripts, workspace directories, logs and result notebooks. The project is distributed as a pip package and offers a manual developer installation that uses Docker. The README includes tutorials, example benchmarks drawn from MLE-Bench, demo materials and pointers to published papers that document the framework and evaluation.
Links
Categorization
App Details




-
 $$$$
$$$$ -
 $$$$
$$$$