characterfile
Basic Information
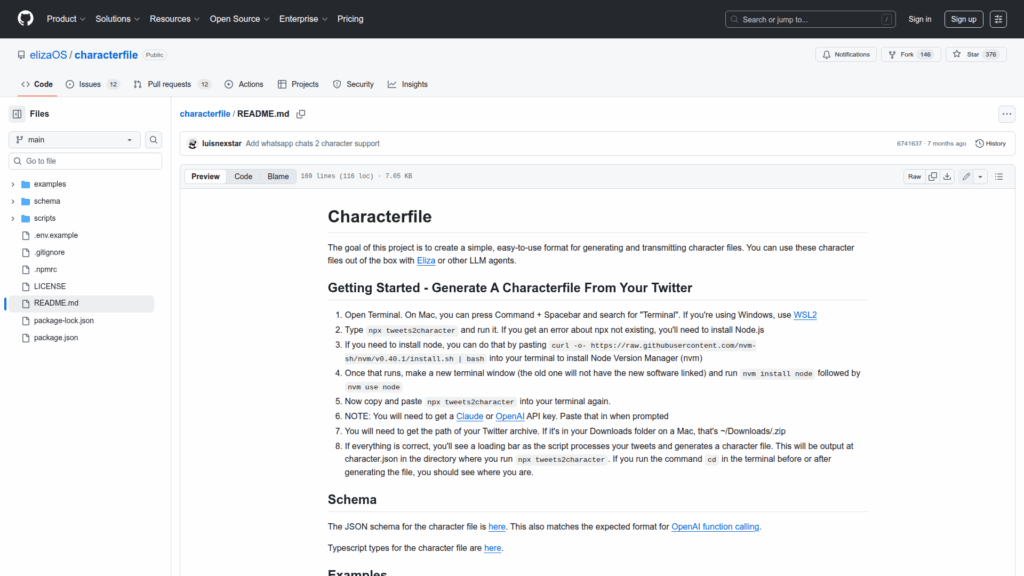
Characterfile provides a simple, easy-to-use JSON format and tooling for generating, validating, and sharing character profiles that can be consumed by Eliza and other LLM agents. The repository includes a formal JSON schema and TypeScript types that define the character file structure, plus example character files and language-specific examples in Python and JavaScript. It supplies command-line scripts to automatically build character files from social data sources such as Twitter archives and WhatsApp chat exports, and to merge extracted knowledge into character files. The intent is to standardize how persona and contextual knowledge are represented so developers can generate interoperable character data for agent behaviour and for use with OpenAI function calling or other LLM integrations. The project documents installation and usage patterns, including API key requirements for OpenAI or Anthropic when needed.
Links
Categorization
App Details




-
 $$$$
$$$$ -
 $$$$
$$$$