FinRL_DeepSeek
Basic Information
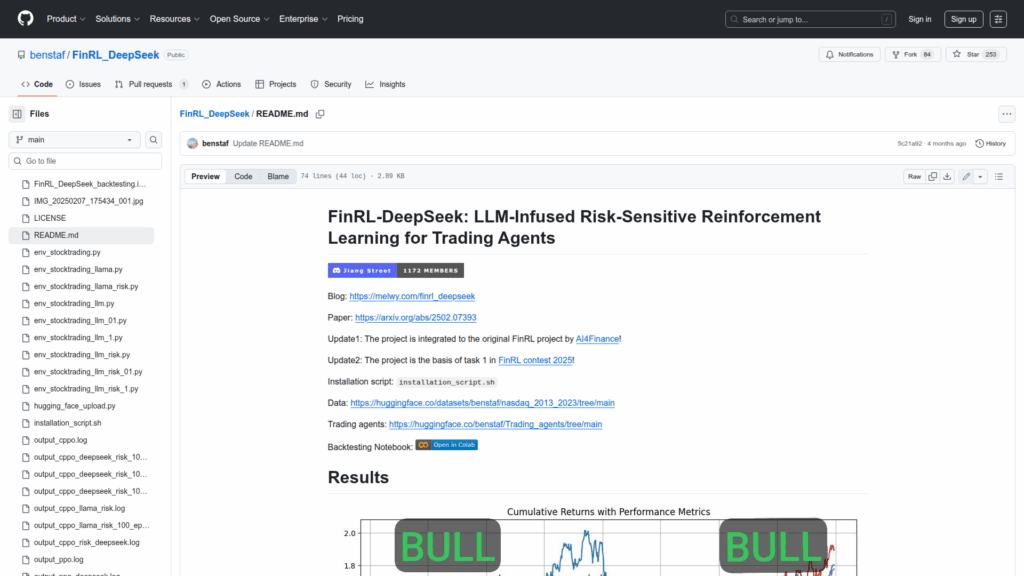
FinRL-DeepSeek implements LLM-infused, risk-sensitive reinforcement learning methods for automated trading agents. The repository packages code and assets to add language model signals to financial reinforcement learning workflows and to train and backtest trading policies. It provides data preprocessing pipelines that combine news sentiment and risk assessments with market data, example environment implementations compatible with FinRL style stock trading gyms, and multiple training entry points for PPO, CPPO and their LLM-enhanced variants. The project is presented as research code accompanying a paper and has been integrated into the upstream FinRL project. The repo also includes a backtesting notebook, an installation script, references to prepared Hugging Face datasets and guidance for running distributed training on a recommended Ubuntu server setup.
Links
App Details
-
 $$$$
$$$$ -
 $$$$
$$$$