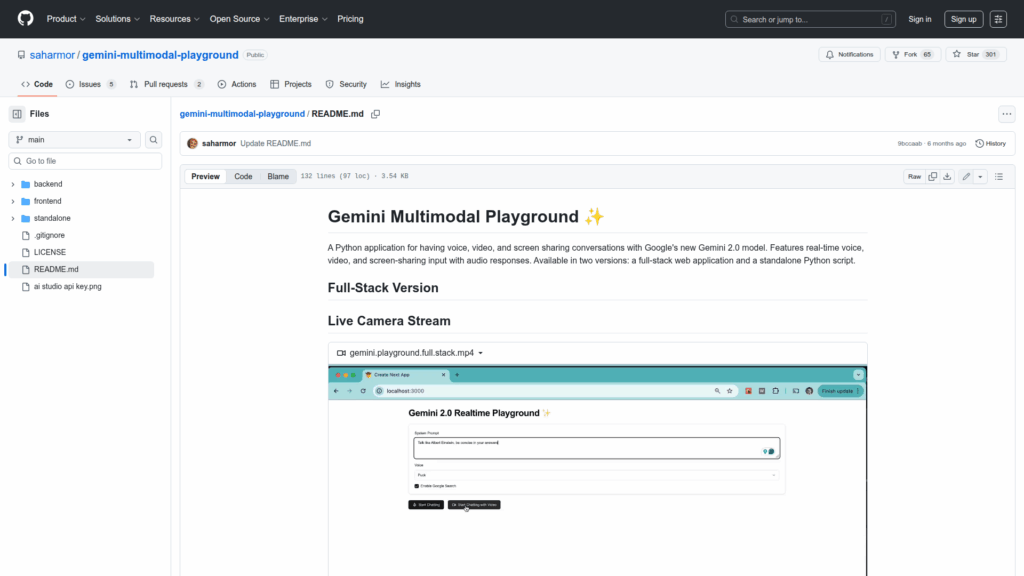
gemini-multimodal-playground
Basic Information
This repository provides a Python application and accompanying frontend for interacting with Google's Gemini 2.0 model using multimodal inputs. It is designed to run real-time conversations that accept voice, live camera video, and screen-sharing input while producing audio responses. The project offers two delivery options: a full-stack web application with a Python backend and a Node frontend, and a standalone Python script that runs as a desktop app. The README documents prerequisites such as Python 3.12+, Node.js 18+, a Google Cloud account, and a Gemini API key, and it explains how to configure the application via environment variables and local servers. The repo is intended as a playground for running, demoing, and experimenting with realtime multimodal interactions with Gemini.
Links
Categorization
App Details




-
 $$$$
$$$$ -
 $$$$
$$$$