Grounding_LLMs_with_online_RL
Basic Information
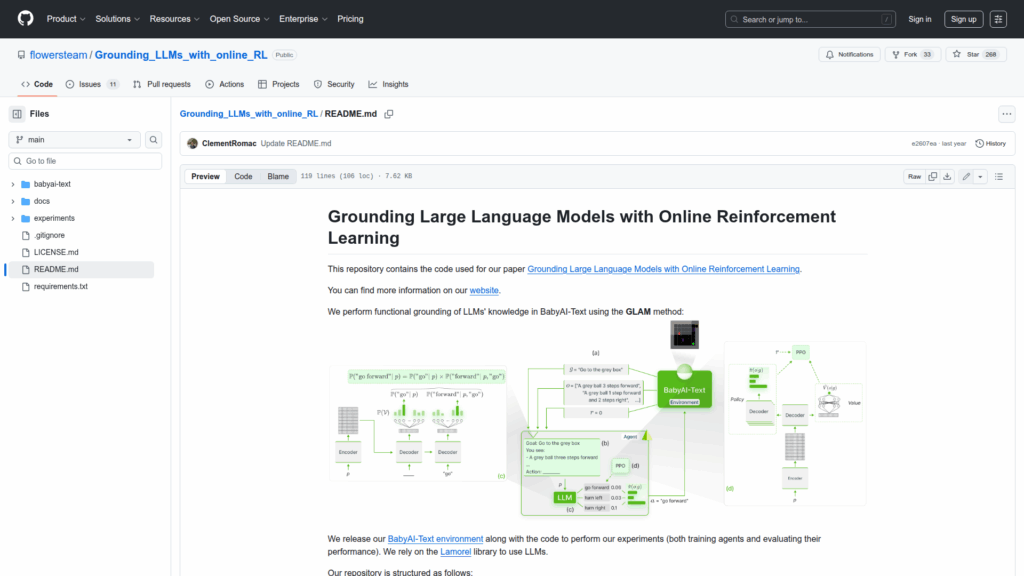
This repository contains the code and environment used to reproduce the experiments from the paper "Grounding Large Language Models with Online Reinforcement Learning." It provides an implementation of the GLAM method to perform functional grounding of LLMs on the BabyAI-Text benchmark and integrates with the Lamorel library to use and fine-tune language models. The repo bundles a custom BabyAI-Text environment, multiple agent implementations, training and evaluation scripts, and configuration/examples to run PPO-based online reinforcement learning with LLMs. The materials are intended for researchers and developers who want to train, evaluate, and analyze how LLMs can be grounded through interaction and reinforcement learning in a controlled simulated environment.
Links
Categorization
App Details

-
 $$$$
$$$$ -
 $$$$
$$$$