llm-leaderboard
Basic Information
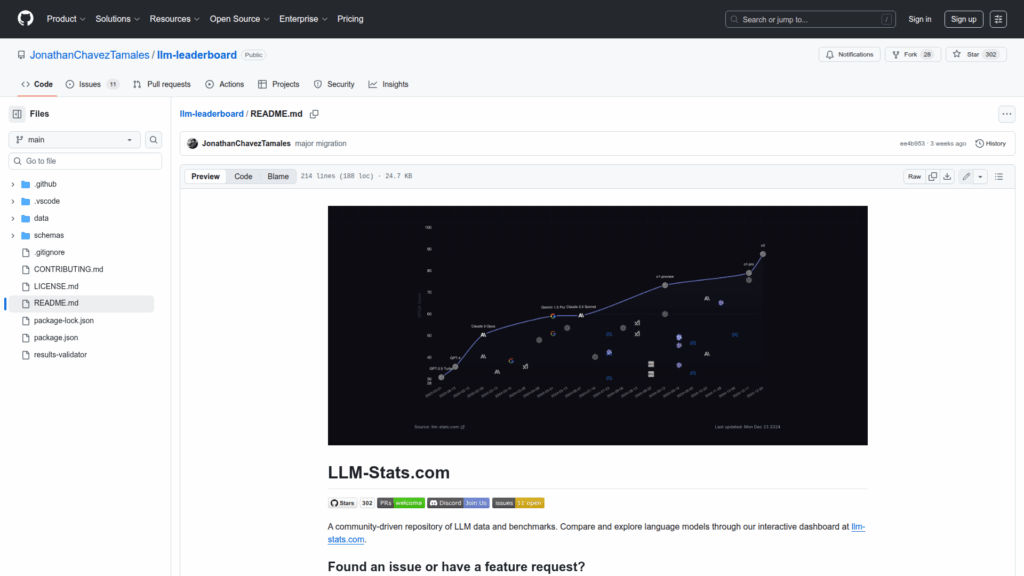
This repository is a community-maintained collection of structured data and benchmark results for large language models. It collects metadata for hundreds of LLMs including model sizes, context window limits, licensing, provider configurations and pricing, and measured performance such as throughput and latency. The project centralizes standardized benchmark scores and organizes all entries so contributors and consumers can compare models side by side. Data is stored under a clear directory layout with schemas for validation and a public contribution workflow. An interactive dashboard is provided to explore and visualize leaderboards and model comparisons. The repo is intended as a reference resource for anyone evaluating or documenting LLM capabilities and for community-driven updates to maintain accuracy.
Links
Categorization
App Details



-
 $$$$
$$$$ -
 $$$$
$$$$