Speech AI Forge
Basic Information
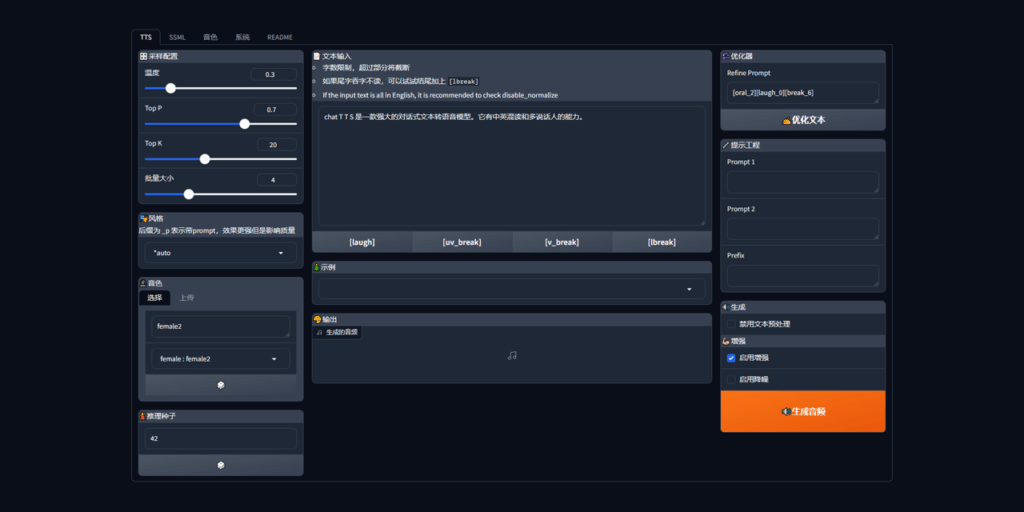
Speech-AI-Forge is a project centered on text-to-speech model development that provides both an API server and a Gradio web user interface for running and managing speech generation and recognition workflows. The repository packages integrations for many open TTS and ASR models and tools, plus scripts to download required model assets. It is intended to be deployed locally, in containers, on Colab, or on HuggingFace Spaces. The codebase exposes a lightweight HTTP API server script for higher-throughput programmatic use and a web UI for interactive configuration and testing. The project focuses on practical TTS features such as multi-model inference, voice building and testing, SSML script editing, long-text handling and post-processing, while also offering ASR, force alignment and audio enhancement capabilities. Model download utilities, Docker compose files, environment templates and API documentation are included to help users install and run the system.
Links
Categorization
App Details





-
 $$$$
$$$$ -
 $$$$
$$$$