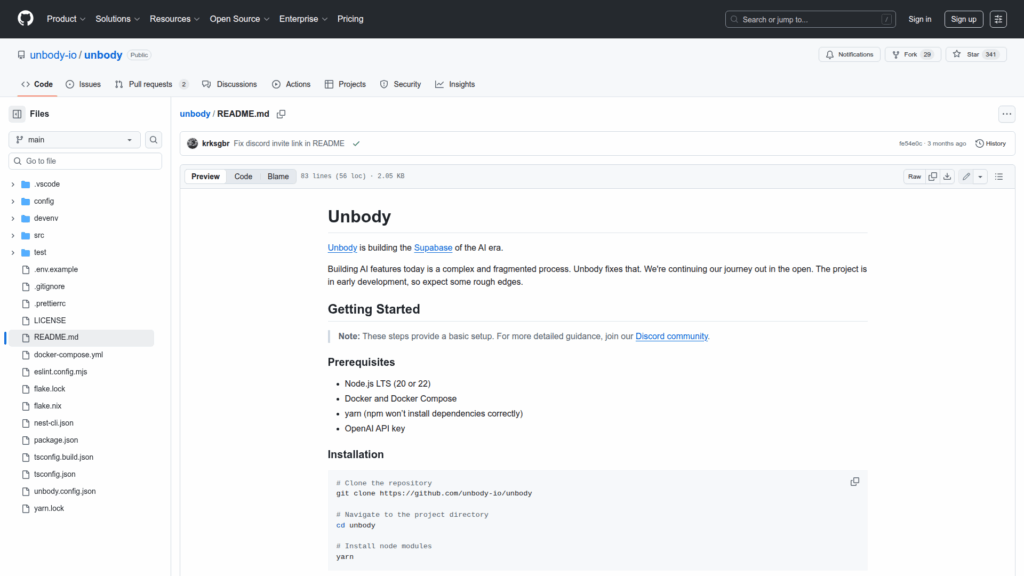
Basic Information
Unbody is an open-source backend platform for developers building AI-native applications, positioned as the Supabase of the AI era. It centralizes the fragmented process of adding AI features by providing tooling for data ingestion, indexing, orchestration and local deployment. The repository contains a Node.js application that runs with Docker and Docker Compose, requires an OpenAI API key, and includes a CLI to add data sources and connect example storage. It is intended for developers to set up a demo project, monitor file indexing with a Temporal dashboard running locally, and iterate on knowledge-focused features rather than static data. The project is in early development and maintained publicly to encourage contributions and community feedback.
Links
Categorization
App Details




-
 $$$$
$$$$ -
 $$$$
$$$$